Mementic
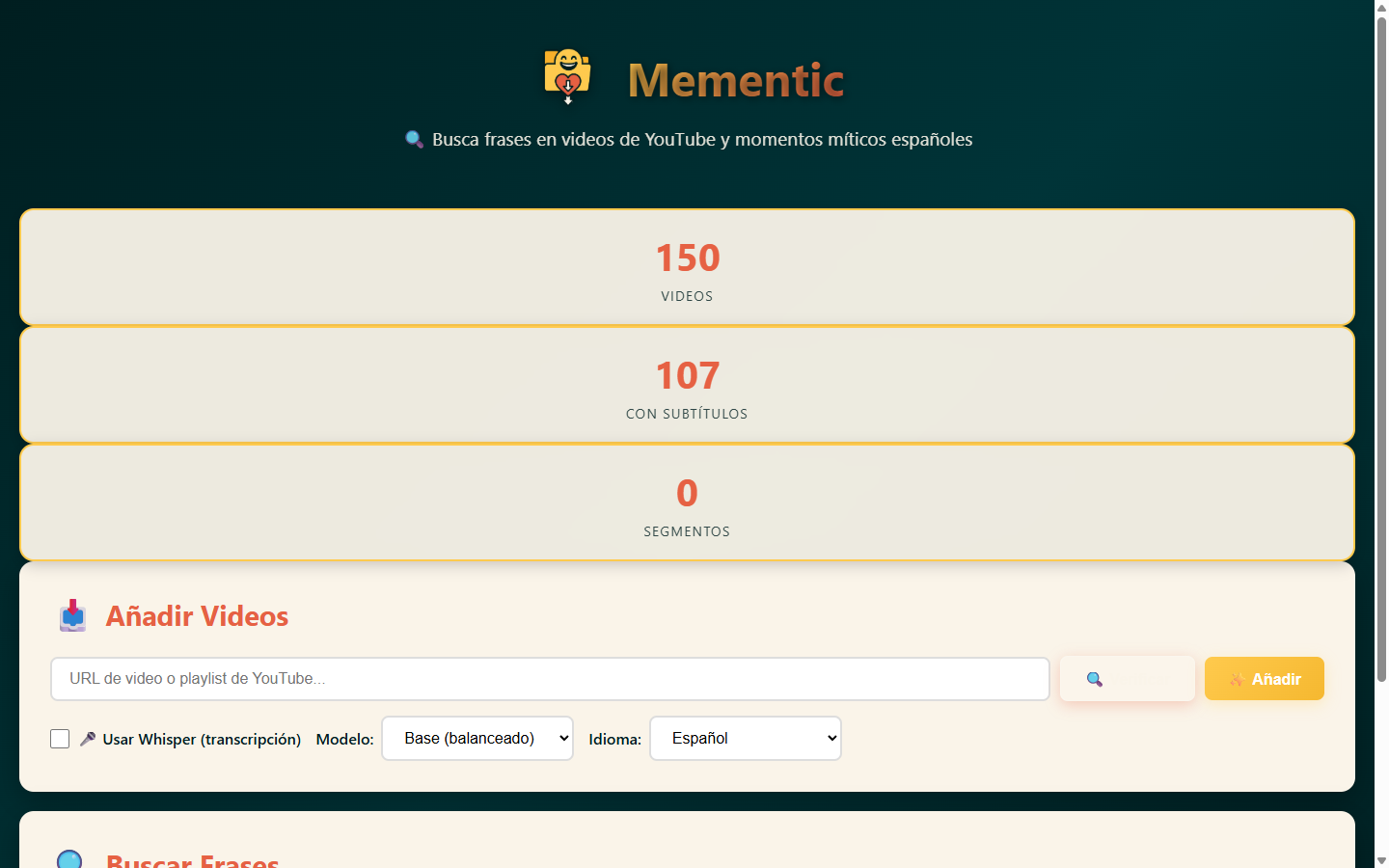
Indexador y buscador de frases en vídeos de YouTube. Ingesta playlists o keywords, transcribe con Whisper cuando no hay subtítulos, y devuelve el clip exacto (start/end) que contiene la frase buscada con búsqueda fuzzy por trigramas.
El Reto
Recordar exactamente en qué vídeo y minuto se dijo una frase es prácticamente imposible. Las búsquedas de YouTube son por título y descripción, no por contenido hablado, y los memes/citas se pierden entre miles de horas de vídeo.
Resultados
- Pipeline FastAPI + SQLAlchemy + PostgreSQL con ingesta idempotente
- Whisper STT cuando no hay subtítulos disponibles en YouTube
- Búsqueda exacta + fuzzy (trigramas) con timestamps por segmento
- Descarga de clips por rango temporal vía endpoint REST
La Solución
Construí un servicio FastAPI que ingiere playlists o keywords de YouTube, descarga subtítulos cuando existen y, si no, los genera con Whisper. Cada segmento se indexa en PostgreSQL con timestamps. Una búsqueda combinada exacta + fuzzy (trigramas) devuelve el vídeo, el clip y los segundos exactos donde alguien lo dijo.
Motivación
Me harté de buscar memes y citas concretas en YouTube sin saber dónde estaban. Si Shazam puede identificar una canción de 5 segundos, debería poder hacer lo mismo con citas habladas.
Retos
La ingesta idempotente fue el reto principal: una playlist puede tener vídeos eliminados, subtítulos que cambian o que no existen y hay que decidir cuándo invocar Whisper (costoso) o aceptar el dato del scraper. La búsqueda fuzzy necesitó normalización agresiva del texto y un índice trigram en Postgres.
Aprendizajes
Aprendí a diseñar un pipeline de ingestión que se puede ejecutar mil veces sin duplicar nada, y a usar PostgreSQL más allá del CRUD básico (extensiones como pg_trgm cambian completamente lo que se puede hacer).
Contexto
MVP funcional con frontend embed de YouTube y endpoint de descarga de clips. Pendiente acceso LAN, ingesta de la primera playlist real y dashboard de duplicados.